集計・データの見える化のプログラムリスト
「データサイエンス チュートリアル」の動画付きチュートリアルの2nd STEPを終え、集計、データの見える化までは、なんとなくやり方がわかるようになってきたと思います。
今まで、出てきたプログラムをリストアップしました。
一通り、動画付きチュートリアルを終えた方は、索引代わりにお使いください。
**********
■1st STEP
#4 Section 2 ライブラリの選択とデータの読み込み
① import ライブラリ名 as ライブラリの略称
② pd.read_excel('データのある場所/データ名.xlsx ')
③ データ名
④ データ名.head()
⑤ データ名.tail()
⑥ len(データ名.index)
⑦ データ名[“列名""]
⑧ データ名[“列名""].unique()
⑨ データ名.dtypes
⑩ pd.read_excel(""データのある場所"", dtype = {“列名"": データ型})
⑪ データ名[“列名”]
⑫ データ名[[“列名”]]
⑬ データ名[データ名[“列名”] > 数字]
⑭ データ名[“列名""].max(axis=0)
⑮ データ名.describe()
⑯ print(“列名"")
⑰ データ名.sort_values(“列名"",ascending=False)
⑱ データ名.astype({“列名”:データ型})
⑲ データ名.iloc[行番号 : ]
⑳ データ名.isna().sum()
㉑ データ名.dropna()
#12 Section 10 queryを使った複数条件での抽出
㉒ データ名.query(“数字1 <= 列名 <= 数字2”)
㉓ データ名.query(“列名 ! = 列名”)
㉔ データ名.query(“列名 == 列名”)
㉕ データ名.query(“論理演算1" and "論理演算2")
#13 Section 11 groupbyを使ったデータのグループ化
㉖ データ名.groupby(“列名”).count()
㉗ データ名.groupby(“列名1”)[“列名2”].max()
㉘ データ名.to_csv(‘保存するフォルダーのパス/新データ名.csv’)
■2nd STEP
㉙ pd.read_csv("データのある場所", parse_dates=["列名"],dtype= {"列名1": データ型, "列名2": データ型})
㉚ データ名.drop("列名", axis=1)
㉛ データ名[“新列名”] = データ名[“列名1”] * データ名[“列名2”]
㉜ データ名[“新列名”] = データ名[“列名”].dt.strftime(“%Y%m”)
#18 Section 16 seabornでグラフ描画(1)
㉖’ データ名.groupby(“列名”).sum()
㉝ import matplotlib.pyplot as plt
㉞ import seaborn as sns
㉟ %matplotlib inline
㊱ sns.barplot(data=データ名, x=“列名1”, y=“列名2”)
㊲ データ名.reset_index()
㊳ データ名.groupby(“列名”, as_index=False).sum()
#19 Section 17 seabornでグラフ描画(2)
㊳ !pip install japanize-matplotlib
import japanize_matplotlib
㊴ plt.figure(figsize=(○, △), dpi=□)
㊵ plt.gca().ticklabel_format(style='plain', axis='y’)
㊶ plt.style.use("ggplot")
㊷ plt.title("グラフタイトル")
㊸ plt.ylim(最小値,最大値)
㊹ from google.colab import files
plt.savefig(“画像ファイル名.jpg"")
files.download(""画像ファイル名.jpg "")
㊺ pd.cut( データ名[“列名”], 分割数, precision=□, right=True )
㊺ pd.cut( データ名[“列名”], 分割数, precision=□, right=True )
㊼ pd.cut( データ名[“列名”], [数字1, 数字2, 数字3] )
㊽ pd.cut( データ名[“列名”], [数字1, 数字2, 数字3] , labels=[ラベル1,ラベル2, ラベル3] )
#21 Section 19 ビンのラベルを元のデータに付与する
㊾ 新データ名 = 元データ名.copy()
㊿ 新データ名[“新列名”] = pd.cut( 元データ名[“列名”], [数字1, 数字2,数字3] , labels=[ラベル1, ラベル2, ラベル3] )
㉖’ データ名.groupby(“列名”).sum()
⑰ データ名.sort_values(“列名”,ascending=False)
51 データ名.query( ‘列名 == [“文字名1”, “文字名2”] ‘)
52 sns.histplot(data=データ名, x=“列名")
53 sns.histplot(data=データ名1, x=“列名")
sns.histplot(data=データ名2, x=“列名")
54 color=‘色’
55 plt.legend(labels=[“A"", “B"", “C""])
56 alpha=数字
57 sns.histplot(data=データ名, x=“列名1”, hue=”列名2“)
58 sns.histplot(data=データ名, x=“列名1”, hue=”列名2“, multiple='stack’)
59 sns.histplot(data=データ名, x=“列名1”, hue=”列名2“, multiple='dodge')
60 sns.displot(data=データ名, x=“列名1”)
61 sns.displot(data=データ名, x=“列名1”, kde=True)
62 sns.displot(data=データ名, x=“列名1”, kind=‘ecdf’)
63 sns.catplot(data=データ名, x=“列名1"", kind='count’)
㊱ sns.barplot(data=データ名, x=“列名1”, y=“列名2”)
64 sns.barplot(data=データ名, x=“列名1”, y=“列名2”, 引数)
64’ sns.barplot(data=データ名, x=“列名2”, y=“列名1”, 引数)
65 sns.countplot(data=データ名, x=“列名1”, y=“列名2”)
66 sns. lineplot(data=データ名, x=“列名1”, y=“列名2"")
67 sns. lineplot(data=データ名, x=“列名1”, y=“列名2“, errorbar=None)
68 plt.xticks(rotation=角度)
69 sns. lineplot(data=データ名, x=“列名1”, y=“列名2“, hue=“列名3”)
70 sns.scatterplot(data=データ名, x=""列名1 "", y=""列名2"")
71 sns.scatterplot(data=データ名, x=""列名1 "", y=""列名2“, hie=“列名3”)
72 plt.legend(loc=‘位置’)
73 import plotly.express as px
74 px.pie(データ名, values=“分類したい列名”, names=“値の列名”)
75 データ名.pivot_table(index=“列名1”, value=“列名2”,aggfunc=‘関数’, 他の引数)
76 データ名[データ名.isna().any(axis=1)]
77 データ名.replace(“元の要素”, “新しい要素”)
78 データ名.apply(関数, axis=1)
79 lambda 引数:処理内容
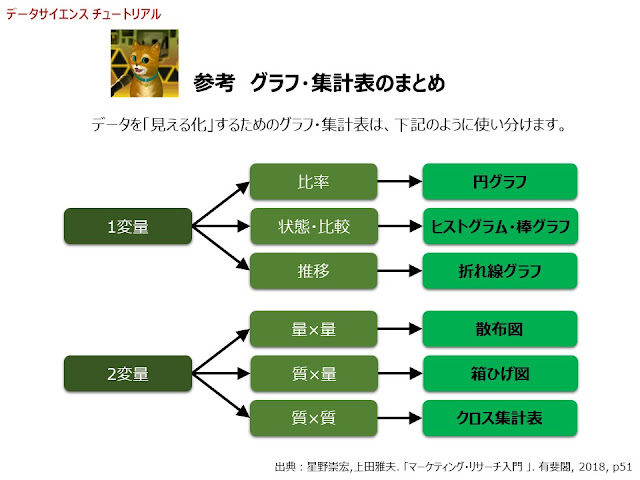
また、データを「見える化」するためのグラフ・集計表の使い分けは、下記のようになります。
コメント
コメントを投稿