#48 Section4 分類(1) 教材の用意&PyCaretのインストール/インポート
ここからいよいよコードの解説に入ります。
→ スライドは、クリックすると拡大できます!

PyCaretが予測の途中でどのような処理や計算をしているかをしっかりと学んでいきましょう。

まずは、教材の準備をしていきます。
PyCaretのホームページから『DOCS』をクリックし、さらに『Tutorials』をクリックします。
『Tutorials』にある『Binary Classification』を今回の教材にします。

【PyCaretホームページ】 https://pycaret.org/
【DOCS】 https://pycaret.gitbook.io/docs
【Tutorials】 https://pycaret.gitbook.io/docs/get-started/tutorials
『Tutorials』にある『Binary Classification』は、教師あり学習に属する分類の一種で、各データを2つのカテゴリー、例えば、「陽性」or「陰性」、「出荷可能」or「出荷不可」のように二つのグループに分類するものです。日本語では、二項分類と呼びます。
次のような用途で使われます。
1.臨床検査で患者が特定の疾病に罹患しているか否かで分類する
2.ある製品が出荷できる品質か、それとも捨てるべきかの判断
3.あるページや記事を検索結果に含めるか否か
4.メールがスパムかどうかを判定する

『Binary Classification』の『Colab』をクリックすると、『Google Colaboratory(以後「Colab」と省略)』の『Tutorial - Binary Classification』という名前のノートブックが現れます。この状態では、まだGoogleドライブに保存されているわけではありませんので、『ドライブにコピー』をクリックします。
『Tutorial - Binary Classification.ipynb のコピー』となっていますので、『Binary Classification』というファイル名にしておきましょう。
また、読み込みに時間がかかるので『Detailed function-by-function overview』以下は、削除しておきます。『Quick start』の部分のみを使います。
ついでに、『マイドライブ』 → 『Colab Notebooks』のフォルダー内に、新しく『機械学習』というフォルダーを作成し、そこに『Tutorial - Binary Classification』を移動します。
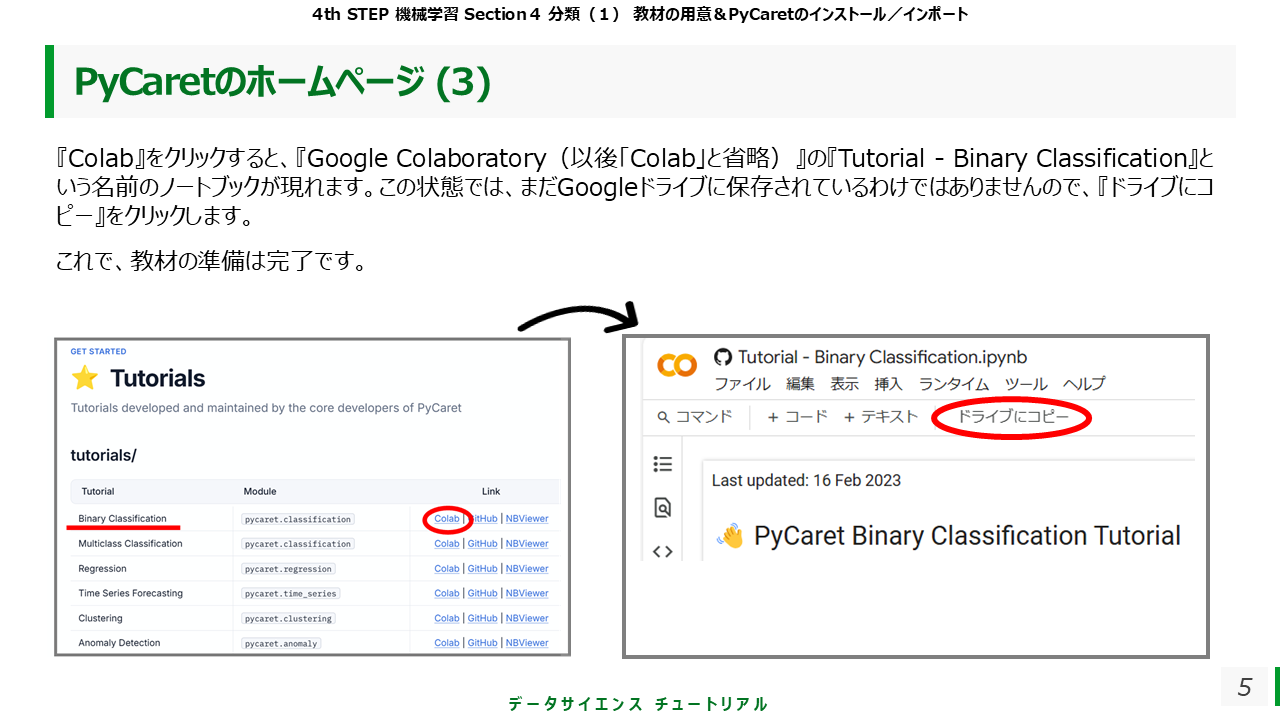
これで、教材の準備は完了です。PCでの操作動画を見てみましょう!
さて、『Binary Classification』を実際に動かしてみましょう!
この教材では、既にコードが書いてありますから、それを見ていきながら、何をやっているのか理解していきましょう!
Colabには、PyCaretがインストールされていませんので、先ずはPyCaretをインストールしましょう。通常の『!pip install paycaret』では、すべてのものをインストールすることはできません。 paycaretに続けて[full]と書くとフルバージョンをインストールすることができます。
その後、実行します。
結構なパーツが含まれていますから、数分待つことになります・・・

ところが、ColabでPyCaretをインポートすると、数分経過してから下記のように『セッションを再起動する』とのアラームが出てきます!Colabは最新に近いパーツで動いていますが、PyCaretはその最新のパーツに対応していないためです。
でも、ご安心を! 『セッションを再起動する』をクリックして、再起動すれば、PyCaretは問題なく稼働します。

とは言え、2024年に入ってから3度のマイナーチェンジをしているので、PyCaretの進化が追いつく努力は続けれらています。
PyCaretは、非常に多くのパーツから成り立っているため、分析環境を構築するために多くの努力が必要とされます。これが、いまいち普及が進まない原因です。解説本も少ない!
通常は、『python3 virtualenv』、『Anaconda』等を使って、仮想環境を作ります(ここでは割愛します)。
次に分析データを読み込みます。
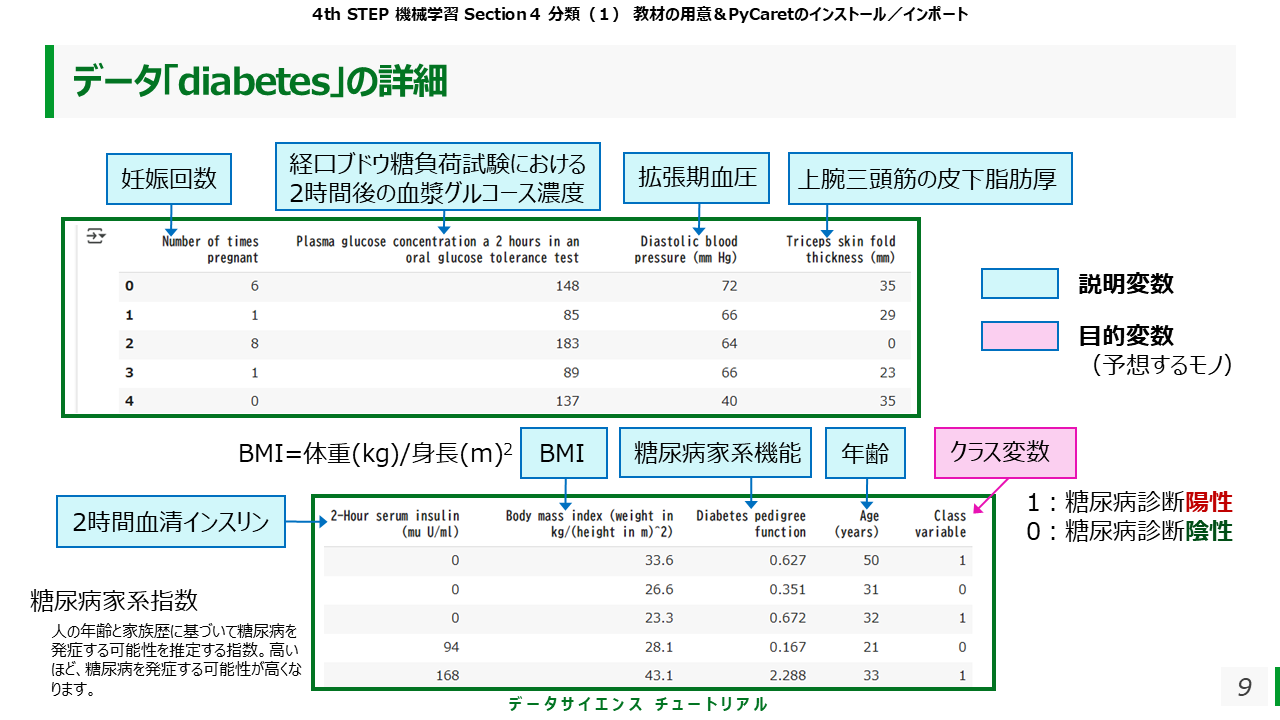
PyCaretには、『diabetes』という糖尿病患者の検査、診断データが入っています。得られたデータを『data』と宣言し、それを下記のようなコードで読み込み、表示させます。
from pycaret.datasets import get_data
data = get_data('diabetes')

データの詳細は、下記のようになります。
1行が一人分のデータになっていて、様々な検査値や属性の列とともに、最後に『Class variable』の列があります。
『Class variable』は、日本語では『クラス変数』と訳し、下記の二つのクラス(グループ)のどちらかに属しているかを表しています。
1:糖尿病診断陽性
0:糖尿病診断陰性
また、様々な検査値や属性は説明変数、『クラス変数』は目的変数になっています。
説明変数とは「何かの原因となっている変数」のことで、目的変数は「その原因を受けて発生した結果となっている変数」のことです。機械学習では、目的変数は予測するモノを指しています。
最後は、『Binary Classification』がどのように動いていくかを動画で確認しましょう。
※ 以前は、pycaret.orgがプロジェクトの概要やニュース、docs.pycaret.org(GitBook)が詳細なマニュアルというように、情報が分かれていました。
返信削除しかし、ユーザーが最も必要とする情報は「ドキュメンテーション(マニュアル)」であるため、プロジェクトのメインURL(https://pycaret.org/)から、その主要なリソース(https://pycaret.gitbook.io/docs/)へ直接誘導することで、アクセスを一本化しているようです。