#33 URLからデータを読み込む

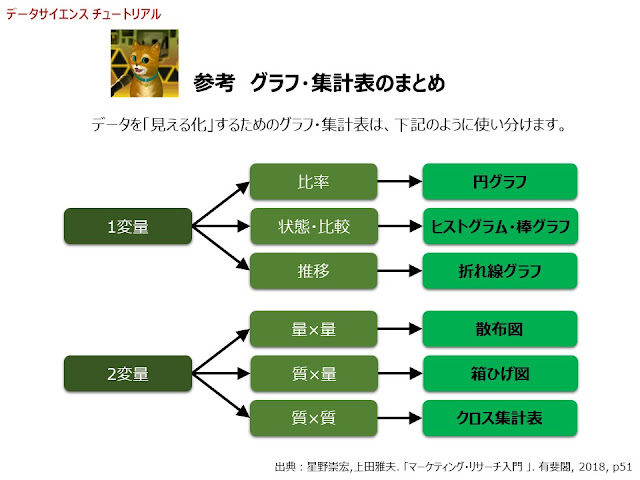
今回は、NDBオープンデータのホームページにあるデータを読込み、見やすい形に整形していきます。 そのために、下記のようなプログラムを解説します。 ● ホームページからダウンロードできるExcelファイルを読み込む 80 url = “Excelファイルのありか" データ名 = pd.read_excel(url) ● Excelの最初の何行かを読み飛ばす「skiprows」、「skipfooter」 81 skiprows=[数字1, 数字2, 数字3, …] ● データの列名を変更する「rename」 82 データ名.rename(index={古い行名1:新しい行名1,…}, columns={古い列名2:新しい列名2,…}) ● 文字列を上下と同じように埋める「fillna」 83 データ名 ["薬効分類"].fillna(method='ffill') ************ ■ まずは、下記の 動画 (8分42秒)をご覧ください。 ■ 次にプログラムの 解説 を自分のペースで読みましょう。 下記のスライドを参照してください。 #33 データの読み込み by @Cat_Taro ************ ■ このセクションのプログラムは下記のようになります。 実際に、コピペして コラボ で試してみましょう! import pandas as pd import numpy as np url1 = "https://www.mhlw.go.jp/file/06-Seisakujouhou-12400000-Hokenkyoku/0000139842.xlsx" df = pd.read_excel(url1) df.head() url1 = "https://www.mhlw.go.jp/file/06-Seisakujouhou-12400000-Hokenkyoku/0000139842.xlsx" df1 = pd.read_excel(url1, skiprows=[0, 1, 3]) df1.head() df1_1 = df1.rename(columns={"薬効...